
Starbucks Review Analysis is a data pipeline and analysis project that predicts the sentiment of a Starbucks review and gives Starbucks location recommendations, showcasing understanding and skills in the AI subfield of Natural Language Processing (NLP).
This project was completed as a qualification case (with three parts) to teach Natural Language Processing (NLP) as a laboratory assistant. I chose a dataset of Starbucks customer reviews because I wanted to learn about the process of sentiment analysis for reviews, and (incidentally) I am an avid coffee drinker. There are three notebooks altogether, which demonstrate a foundational data pipeline, from raw data ingestion and cleaning to feature extraction and modeling. From this project, I developed skills in data manipulation, text processing, and building predictive models, which are fundamental to a data engineering workflow.
Tech Stack: Python with libraries Pandas, NLTK, Scikit-learn, Matplotlib, spaCy, pickle (requirements.txt for setting up virtual environment)
Dataset
The data for this project was sourced from a Kaggle dataset created by web scraping the ConsumerAffairs website. It provides a comprehensive collection of consumer reviews and ratings for Starbucks, offering valuable insights into customer sentiment.
The dataset contains the following columns:
- Name: The reviewer’s name.
- Location: The location or city associated with the reviewer.
- Date: The date the review was posted.
- Rating: The star rating given by the reviewer (1 to 5).
- Review: The full text content of the review.
- Image Links: Links to any images included with the reviews.
Key Features
Case 1: Starbucks Reviews Sentiment Analysis with Naive Bayes
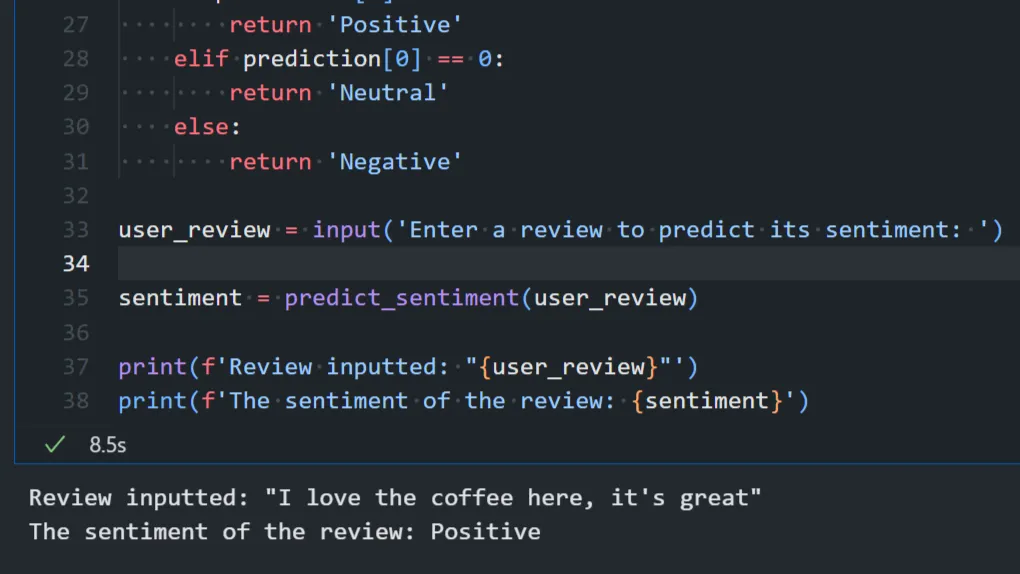
- Data Ingestion & Cleansing → Loads the
.csvfile into a Pandas DataFrame, drops rows with missing values, and converts date strings to a standard datetime format for analysis. - Exploratory Data Analysis (EDA) → Visualizes key trends to find insights such as the distribution of ratings, the states with the most reviews, and the busiest months.
- Text Preprocessing → Cleans raw text by removing special characters, tokenizing words, removing stop words, and performing lemmatization.
- Frequency Distribution → Finds the most common words in positive and negative reviews to understand sentiment drivers.
- Model Building & Persistence → Trains a Complement Naive Bayes (ComplementNB) classifier for sentiment analysis and saves the model using Pickle. ComplementNB is excellent for imbalanced datasets like these.
Case 2: Starbucks Location Recommendations
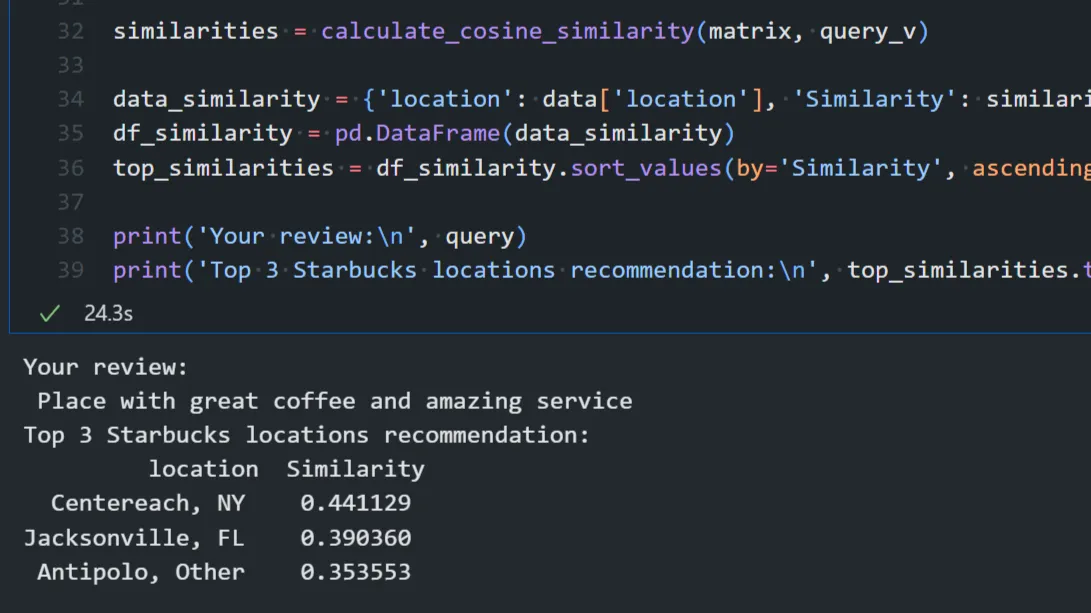
- N-Gram Modeling → Implements an n-gram model to analyze word sequences and calculate text similarity.
- TF-IDF for Similarity → Uses TF-IDF to vectorize text data and calculate cosine similarity to recommend similar Starbucks locations based on a user’s review.
- Named Entity Recognition (NER) → Uses spaCy to identify and extract entities like locations, organizations, and people from review text.
Case 3: Grammar Parsing using Natural Language ToolKit
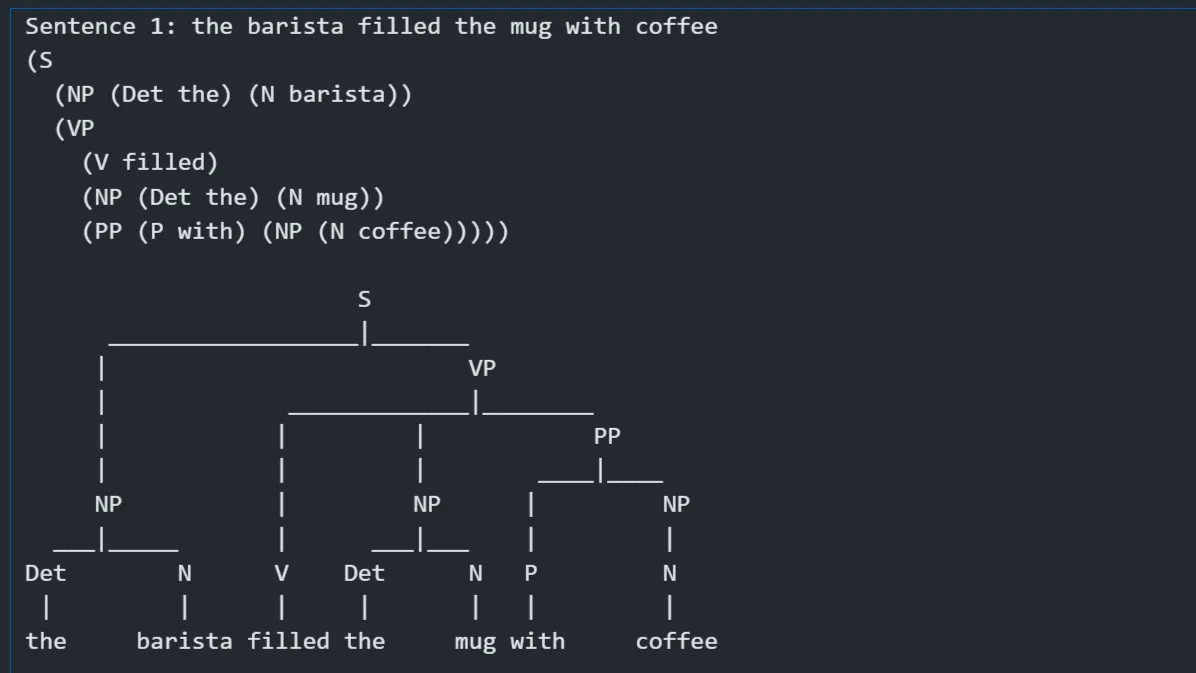
- Context-Free Grammar (CFG) → Defines a simple grammar using NLTK to demonstrate how to parse sentences and understand their syntactic structure.
- Syntactic Analysis → The parser builds parse trees for sample sentences, visually representing their grammatical structure.